The Anatomy of an Android Crash: From Exception to Stack Trace

How often have you been using an interesting Android app, only for it to crash unexpectedly? No one wants to use an app that crashes frequently—it disrupts the experience and negatively affects the user’s trust.
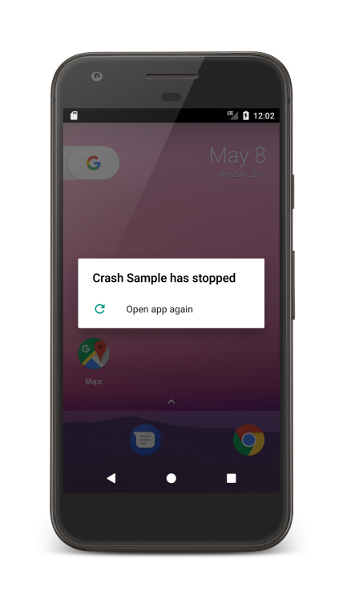
Android crashes are unexpected and abrupt terminations of applications that may occur for many reasons. One such reason is when an app encounters an unhandled exception that it cannot process, leading to its sudden termination.
Research has shown that Android app users can only tolerate an average of 0.25% of application crashes and will abandon your app if the crashes exceed 0.75%. Another study by DCI found that 62% of users uninstall an app after experiencing a crash. This highlights the importance of minimizing crashes to improve your app’s retention rate. Higher retention leads to more engaged users and, ultimately, increased revenue. Reducing crashes directly boosts retention, making it a key priority for your app’s success.
Understanding crash analysis is important for debugging because it provides detailed information about the state of your Android application when it crashes. This allows you to pinpoint the exact cause of the crash, identify the problematic code section, and efficiently fix the issue, thus significantly improving your user experience.
In this article, you will learn why Android app crashes happen. You will learn to identify the key components of an Android crash, starting with the initial exception that triggers it. This article will guide you through interpreting stack traces, which are important for pinpointing the exact location and cause of the crash in your code.
To avoid spending time on manual analysis, you can also use tools like Bugsee, which automatically capture crashes, logs, and app activity before the error. This significantly speeds up the debugging process.
Fundamentals of Exception-Driven Crashes in Android
Unhandled exceptions are one of the causes for Android application crashes. Understanding how exceptions are thrown, caught, and managed is important to debugging and resolving these crashes. In this section, we will walk you through the basic concepts of exception handling and how they ultimately lead to an application crash when not properly managed.
How Exceptions Are Thrown
In Java or Kotlin, exceptions are thrown when a part of the program encounters an error or an unexpected condition, thus disrupting the normal execution of the program’s instruction. Exceptions are objects that encapsulate information about the error, including the type of exception, a message describing the problem, and optionally a stack trace showing where the error occurred.
For example, the NullPointerException is a common exception that is thrown when an application tries to use an object reference that is null. When this happens, the JVM immediately halts the normal flow of the program and throws the exception. In the following contrived example, we demonstrate how the exception is both thrown and caught.
import android.os.Bundle;
import android.widget.TextView;
import android.appcompat.app.AppCompatActivity;
public class NullPointerExampleActivity extends AppCompatActivity {
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
TextView textView = findViewById(R.id.textView);
// set object to null, this will cause an exception to be thrown
textView = null;
// Check if the object is null before using it
try {
textView.setText("Object is not null. Or is it?");
} catch (NullPointerException e) {
e.printStackTrace();
}
}
}Whenever an exception is thrown, it propagates up the call stack along the call chain in search of a catch statement. In case the exception reaches the main method of the app without being caught, it will invoke applications “unhandled exception handler” and terminate the app.
Catching Exceptions
In some cases you, as a developer, know and anticipate a specific code path may or will throw under some conditions. Ideally, you should catch the exception and recover without crashing (either by retrying and/or gracefully degrading the functionality). As shown in the example above, the way to do it is to wrap the execution in a try-catch block. In certain scenarios, a developer might choose to catch an exception not with the intent to fully resolve the underlying issue, but to perform targeted cleanup, log critical diagnostic information, or wrap the original exception with a more meaningful, contextually rich alternative that provides additional insight into the failure’s root cause or broader system implications.
try {
…
} catch (NullPointerException e) {
db.cleanUp();
myCustomLogger.log(“again, we got this annoying null exception”, e)
throw new MyAppCustomException(“.....”)
}Checked vs. Unchecked Exceptions
In Java, exceptions are divided into two categories: checked and unchecked.
- Checked exceptions (e.g., IOException) are exceptions the compiler (and the IDE) forces you to handle in your code. They typically occur due to external conditions (e.g., file not found, network failures) and must be caught or declared in the method signature. If a method marked as it can potentially throw some type of an exception, you as a developer are forced to handle it by implementing a try/catch block at some location on the execution path of that code.
- Unchecked exceptions (e.g., NullPointerException, IllegalStateException) are subclasses of RuntimeException. These exceptions typically result from logical errors in the code (e.g., accessing a null object or using a closed Scanner). They do not need to be explicitly handled, but if left unhandled, they often result in app crashes.
What an Exception Contains
An exception contains the following common elements:
- Class of the Exception: , NullPointerException, ArrayIndexOutOfBoundsException, or IllegalArgumentException, or others. New exception classes can be created by means of inheritance.
- Message: The exception often contains a message providing more details about the error, such as “Array index out of bounds” or “Object is null.”
- Stack Trace: This provides a list of active method calls from where the exception was thrown, thus helping you trace the exact location in the code where the problem occurred.
The Role of the Exception Final Handler
In Android, if an exception is not caught anywhere in your code, it reaches the application’s final exception handler which is provided by the Android Runtime. This final handler is responsible for stopping the app and generating a crash report.
Default Android implementation is quite simple, it just dumps the exception in the log and terminates the app. Third party in-app crash reporters like Bugsee add their magic and collect additional information which helps developers debug their app after the fact. Tools like Bugsee do that by overriding the implementation of the handler and storing a reference to the original implementation at the launch of the app. Then, whenever a crash occurs, prior to executing the original handler, it has the opportunity to run custom code to collect that additional context and package it for further delivery to its crash reporting analytics backend service.
Other Types of Android Crashes
While uncaught exceptions are a major contributor to Android apps’ crashes and we mainly focus on these in the following article, it wouldn’t be fair not to also mention other types of crashes that do not fall under that category.
Native Crashes in Android
Not all crashes happen within Java or Kotlin code, which are executed within a JVM. Some crashes occur either within native system libraries, or natively linked libraries brought by the frameworks used or implemented by app developers themselves.. Typically such crashes occur due to incorrect usage of memory, the underlying hardware failure, etc. Unlike Java crashes, where exceptions are thrown and handled within the JVM as shown above, native crashes result in signals like SIGSEGV (segmentation fault) or SIGABRT (abort) being sent to the process running the app, which causes the process to terminate.
In a sense, signals are similar to exceptions: it is possible to override a signal handler to do additional data collection before the crash. Unlike exceptions, however, in most cases it is not possible for the process to recover, and the constraints on what can and can not be executed within a handler are very tight. In Android, the Native Development Kit (NDK) provides tools for building, debugging, and profiling native code. When a native crash occurs, Android captures a native stack trace (similar to Java stack traces) and often writes it to a log file (e.g., Logcat), making it available for postmortem debugging.
Below is an example of an Android NDK setup that triggers a native crash by causing a segmentation fault in the native code:
Native Crash in Android Code Example
Java code (JNI binding):
public class NativeCrashExample {
// Load the native library (compiled C/C++ code)
static {
System.loadLibrary("nativeLib");
}
// Declare a native method that will trigger the native crash
public native void triggerNativeCrash();
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
// Trigger the native crash when the app starts
triggerNativeCrash();
}
}
C/C++ code (native implementation):
#include <jni.h>
#include <stdio.h>
#include <signal.h>
#include <stdlib.h>
// A function that triggers a segmentation fault (SIGSEGV)
void causeSegFault() {
int *ptr = NULL;
*ptr = 42; // Dereference a null pointer, causing a segmentation fault
}
// JNI function that will be called from Java
JNIEXPORT void JNICALL
Java_com_example_NativeCrashExample_triggerNativeCrash(JNIEnv *env, object obj) {
causeSegFault();
}In the above code snippet example, the causeSegFault() function attempts to write to a null pointer, triggering a segmentation fault.
As mentioned above, when this native crash occurs, the app does not throw a Java exception because it happens outside the Java Virtual Machine (JVM). Instead, the operating system sends a signal (like SIGSEGV), which is handled by the system’s signal handler. Android’s debugging tools, such as Logcat or NDK stack traces, can be used to capture the crash details.
ANR (Application Not Responding) Crashes
An ANR (Application Not Responding) crash occurs when an Android app becomes unresponsive for too long, typically 5 seconds on the main thread (UI thread), prompting the user to either wait or force-quit the app. Typically, an Android operating system detects this condition and terminates the app. In this case, however, it is not clear where exactly the app spends its time, the exact stack trace can not be retrieved.
There are some mechanisms to instrument and create some heuristics to detect and some conditions before the system detects it, but these usually are not very reliable and do come at some cost, mainly the app performance.
Common Causes of ANRs
- Long-running operations on the main thread: Performing heavy computation or blocking I/O operations on the UI thread can lead to an ANR. The UI thread should be reserved for tasks that affect the user interface, while intensive operations should be offloaded to background threads or handled asynchronously.
- Unresponsive broadcast receivers or services: If a broadcast receiver or a service takes too long to process its tasks, it can trigger an ANR.
- Deadlocks or infinite loops: When threads are waiting indefinitely for resources or fall into infinite loops, the app can become unresponsive.
Example of ANR Scenario
Below is an example of how an ANR can happen due to heavy computation on the main thread:
import android.os.Bundle;
import android.appcompat.app.AppCompatActivity;
public class ANRExampleActivity extends AppCompatActivity {
@Override
protected void onCreate(Bundle savedInstanceState) {
super.onCreate(savedInstanceState);
setContentView(R.layout.activity_main);
// Simulating a long-running operation on the main (UI) thread
performHeavyComputation(); // This causes the app to become unresponsive
}
private void performHeavyComputation() {
// Perform a time-consuming task on the main thread, causing an ANR
for (int i = 0; i < 1000000000; i++) {
// Simulate heavy computation
Math.sqrt(i);
}
}
}In this example, a computationally expensive task is performed on the main thread, causing the UI to freeze. Since the system expects the main thread to be free to handle UI updates and user interactions, this unresponsiveness will result in an ANR.
Avoiding ANRs
To avoid ANRs, you as a developer should follow best practices such as:
- Move heavy operations off the main thread: Time-consuming tasks like network requests, database operations, and large computations should be run on background threads using Android’s threading mechanisms such as AsyncTask, HandlerThread, or Executors.
- Use Looper and Handler properly: These tools allow communication between background threads and the UI thread, making it possible to update the UI after completing heavy tasks.
- Optimize broadcast receivers and services: Ensure they don’t take too long to execute. For example, move long-running tasks in services to worker threads.
Anatomy of a Stack Trace
A stack trace is a snapshot of the call stack at the precise moment when an error or exception occurs in a program. It is a powerful debugging tool that helps you identify the exact location of the problem in the code.
Stack trace is a collection of frames. Each frame represents a method call, starting with the method that encountered the error and working backward through the chain of method invocations that led to that point.
For example, if methodA() calls methodB(), and methodB() encounters an exception, the stack trace will show that methodB() is the point where the error occurred (the top frame, or frame 0), and methodA() is the method that invoked methodB() (frame 1). Each frame can provide crucial information about where the error originated, ideally including the exact line number in the code and the class- or function-responsible for the call.
Dissecting the Stack Trace
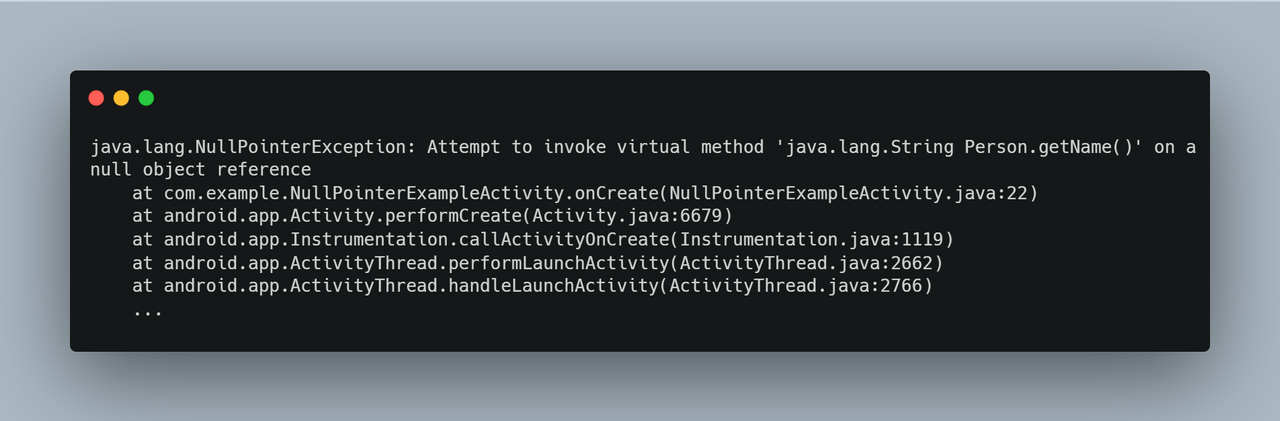
Consider the following stack trace, which was generated when an IllegalStateException occurred:
Exception in thread “main” java.lang.IllegalStateException: Scanner closed
at java.util.Scanner.ensureOpen(Scanner.java:1070)
at java.util.Scanner.nextLine(Scanner.java:1540)
at com.example.IllegalStateExceptionExample.main(IllegalStateExceptionExample.java:12)
This stack trace represents the order of method invocations that led to the crash, beginning with the most recent method call (where the error occurred) and moving backward in the call chain. Let’s analyze this stack trace line by line:
1. The Exception
Exception in thread “main” java.lang.IllegalStateException: Scanner closed
This first line tells us that an IllegalStateException was thrown because the Scanner object was used after it had been closed. In Android, such exceptions occur when a method is invoked at an inappropriate time, violating the object’s internal state.
2. The ensureOpen() method
at java.util.Scanner.ensureOpen(Scanner.java:1070)
This line points to the ensureOpen() method within the Scanner class, a built-in Java utility. The method checks if the Scanner is open before performing any input operation. Since the Scanner was closed, this method throws the IllegalStateException. This part of the stack trace shows the failure that occurred in the core Java API.
3. The nextLine() method
at java.util.Scanner.nextLine(Scanner.java:1540)
The nextLine() method was called to read input from the console, but since and it seems that prior to reading it called the ensureOpen() method to validate the connection is open. This also seems to be happening deep within the core Java API.
4. The Main Method (User Code)
at com.example.IllegalStateExceptionExample.main(IllegalStateExceptionExample.java:12)
The final frame points to line 12 in the user code (IllegalStateExceptionExample.java). This is the location where the closed Scanner was incorrectly used, causing the crash. This frame helps you pinpoint the exact place in the code where the issue occurred.
Code obfuscation
Code obfuscation, using tools like ProGuard or R8, can complicate the process of extracting stack traces by altering method and class names during the build in order to reduce APK size and enhance security. To make these stack traces readable again, deobfuscation is necessary, This can only be done using the mapping files generated during the obfuscation/build process. The topic of obfuscation deserves its own article, stay tuned, as we are planning to cover it in the near future as part of our Android series.
Best Practices for Analyzing Android Stack Traces
In this section, you will learn about the best practices for analyzing your Android stack traces.
Locating the Root Cause
When faced with an Android crash, the first thing to do is to identify the root cause—this is the most important step in debugging. A stack trace provides valuable insights into the sequence of method calls leading up to the crash. To locate the root cause:
- Start from the top: The first line of the stack trace usually contains the type of exception thrown (e.g., NullPointerException, IllegalStateException). This immediately provides clues about what went wrong.
- Examine the method calls: The lines following the exception indicate the method calls that led to the crash. The most recent method calls are at the top, and by inspecting these, you can often pinpoint the exact file and line number where the issue occurred.
- Use line numbers and file references: Every entry in the stack trace contains references to the source code file and the exact line number where the crash happened. This helps narrow down the investigation to a specific section of the codebase.
Patterns to Look For
Certain patterns in stack traces can indicate recurring issues in the code:
Common Exceptions
Exceptions like NullPointerException, ArrayIndexOutOfBoundsException, or IllegalArgumentException are often caused by coding errors. If you see these types of exceptions repeatedly, you must audit how null checks, array bounds, or input validation are handled in your code.
Method Repetition
When a particular method or class repeatedly appears across multiple stack traces, this can point to architectural or design flaws. This isn’t just about one-off coding mistakes—it could indicate something deeper, such as a component that is not robust enough to handle certain scenarios. Method repetition is beneficial when analyzing crash reports from multiple devices or users:
- Systemic Memory Leaks: If an OutOfMemoryError appears repeatedly in stack traces involving certain operations (e.g., image processing or data-heavy workflows), it may indicate that resources like bitmaps or large data objects are not being properly released. Investigating memory management strategies, such as efficient use of Bitmap or proper use of resource-cleaning mechanisms (e.g., try-finally blocks), can address this.
- Threading and Synchronization: In multithreaded environments, if certain methods appear across multiple crashes, there may be issues with race conditions or improper synchronization. Investigate whether resources are being shared safely across threads.
Error Chains and Nested Exceptions
In some cases, crashes occur due to nested exceptions, where one failure leads to another, creating a chain of errors. A single stack trace may not provide enough information to understand the full scope of the problem. Often, the root cause is hidden behind a higher-level exception, making it essential to trace backward through multiple exceptions.
Understanding Nested Exceptions
Nested exceptions, or chained exceptions, occur when an initial error leads to subsequent failures that mask the original issue.
For example, consider the following scenario:
- Network Request Failure: A network call fails due to a SocketTimeoutException.
- Data Handling Error: The failure causes a null response, which is passed to another method that expects valid data. This results in a NullPointerException.
- Cascading Failure: The null value continues through various method calls, eventually leading to a RuntimeException.
Distinguishing Between App and Third-Party Code
Modern Android apps rely heavily on third-party libraries for networking, UI, and other functionalities. Differentiating between issues in your app and those in external libraries is essential when analyzing stack traces:
- Look for familiar packages: Stack trace lines that include your app’s package name indicate issues within your code. Focus on those lines first, as they represent areas you have control over.
- Identify third-party library calls: Libraries like Retrofit, Glide, or OkHttp often appear in stack traces. When you see such libraries, it’s important to consider whether the crash is caused by incorrect use or a bug within the library itself.
- Check for external dependencies: To distinguish between app code and third-party code in a crash scenario, focus on identifying the source of the error in the stack trace. App code typically resides within the package namespace specific to your project, whereas third-party code is often located under different namespaces that correspond to external libraries or SDKs. By looking at the package names and class hierarchies in the stack trace, you can separate crashes originating from your code from those caused by third-party libraries.
If the crash is traced back to a third-party SDK or API, it’s important to investigate the library’s documentation and known issues. Many third-party libraries have specific configuration requirements or usage guidelines to avoid common pitfalls.
By following these best practices, you will be better equipped to decode stack traces, distinguish between different types of issues, and ultimately resolve crashes more effectively.
Track, Analyze, and Manage Applications Errors With Bugsee
Unfortunately, relying just on stack traces is often not enough to get to the bottom of the crash or a series of crashes. While stack traces can indeed show you the location within the code, in many cases this is not enough to understand what exactly happened and what conditions preceded the crash.
To effectively manage app crashes and errors from the field, it’s important to implement a robust system that handles unhandled exceptions, persists crash data without disrupting the user experience, and packages this information for later analysis. This is the area where Bugsee shines. Not only does it collect everything that preceded the crash, including a recording of a screen, user interactions, network traffic, logs, and much more, it completely automates the process of collection of crashes from the field at scale and processing it using a scalable backend infrastructure.
Bugsee interactive dashboard allows identifying patterns, and combining similar crash reports for easy analysis. This saves development teams the complexity of building such a system from scratch, giving them a comprehensive tool to track, analyze, and resolve issues efficiently. With Bugsee, you can focus on fixing bugs without the overhead of managing error reporting infrastructure.
As we are speaking about stack traces, it is worth noting that Bugsee UI is implementing custom heuristic, and when presenting a stack trace, attempts to emphasize to the developer the important frames that might actually be the culprit while hiding the benign and irrelevant ones,
Wrapping Up
In this article, you learned about the different types of Android application crashes and why they occur. We touched on the importance of understanding how exceptions work and how stack traces provide crucial insights into the causes of crashes. You also learned how analyzing crash reports can help improve app stability and user experience by identifying and addressing the root causes of issues.
It is worth reiterating that handling crashes at scale requires advanced tools to gather crash reports, analyze patterns, and provide additional context for debugging. Bugsee offers a complete crash management system that captures native and Java stack traces, records user actions, and provides system logs leading up to the crash. This can be invaluable when working with crashes caused by complex interactions or hard-to-reproduce bugs. Try Bugsee today and see how it simplifies crash handling and reporting for your Android apps.